The i2b2 Web Client is an easy to use data query platform that is used by researchers to perform searches on electronic health records. This is done using a simple drag-and-drop interaction where users browse (or search) a list of medical diagnoses and then drag those terms into various areas of a query builder window. The general layout is shown below: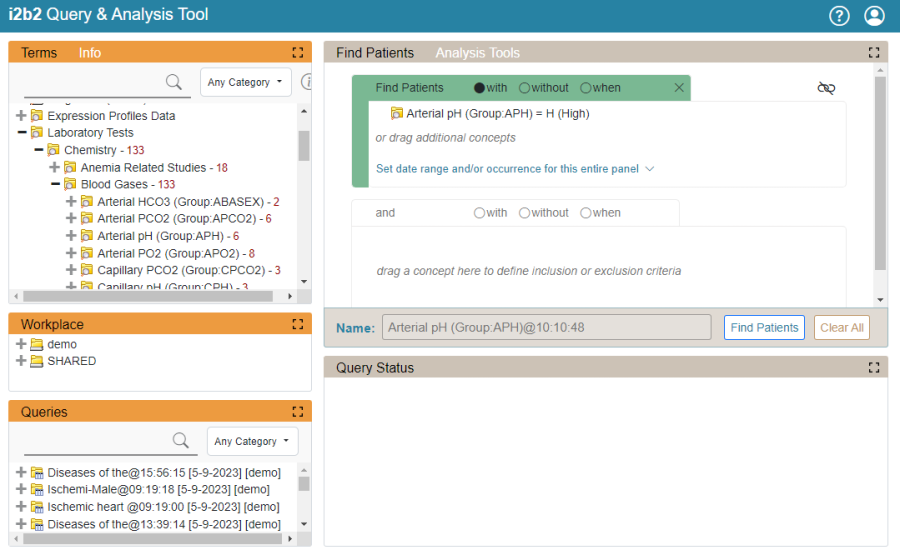
On the upper left is the "Terms" window which contains search terms. On the upper right is the "Find Patients" window which is used to build the query. Also on the upper right is the "Analysis Tools" window which displays a list of plugins (both new and legacy) that a user can access by clicking on the title. This "Analysis Tools" window is where you go to access your plugin in development.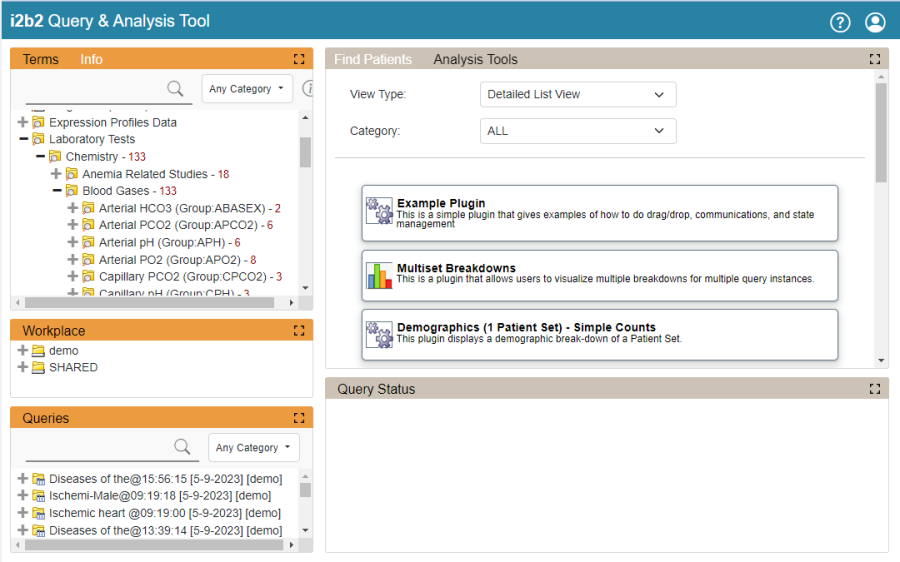
System Design
In general, i2b2 is designed to operate using a services-oriented architecture. An i2b2 "hive" is a collection of services called "cells". The primary i2b2 services are: PM / Project Management which manages projects/users in the hive, ONT / Ontology which stores all the terms that are used to select patients, CRC / Clinical Research Chart which is the central repository of patient data within the hive, WORK / Workplace which allows users to store information for later use. On the server, each one of these cells exposes their services through a different URL. Because of this the i2b2 web client requires the use of a proxy service to overcome the "same-origin" security restrictions that exist within all web browsers. This means that users of the i2b2 web client access the web client when it is hosted on a web server which also has some kind of proxy service capability, connecting the in-browser code to the i2b2 hive of services.