Design_and_Architecture.doc
Informatics for Integrating Biology and the Bedside

i2b2 Design Document
NLP
![]()
c
linical
T
ext
A
nalysis and
K
nowledge
E
xtraction
S
ystem
|
Document Version: |
1.0 |
|
I2b2 Software Release: |
1.6 |
Table of Contents
2.1.3 The NLP processing pipeline
Document Management
|
Revision Number |
Date |
Author |
Description of change |
|
1.0 |
04/12/12 |
Pei J. Chen |
Initial Draft |
|
|
|
|
|
There is a wealth of information within the plain text clinical narrative. The purpose of this cell is to harness the unstructured information by allowing i2b2 users to query and join that information with existing i2b2 concepts. Currently, the entire note is commonly stored as a single row in the observation_blob field in the observation_fact table in i2b2. One of NLP cTAKES’ features is its capability to ‘read’ through and extract concepts from plain text notes and transform them into structured and normalized information. The purpose of this cell is to incorporate cTAKES and i2b2 by formatting the output of cTAKES into the i2b2 observation_fact table format (facts, concepts, modifiers, and values) which can then be easily queried by existing i2b2 interfaces.
There will be 2 main components:
- An administrative tool (cTAKES GUI) that will allow users to specify the input DataSource of the note(s), the output of the notes(s), and the NLP pipeline to be used. The cTAKES GUI will be designed to be a web interface (packaged a war file to be easily deployed to standard servlet containers such as Tomcat). The configuration information will be stored and could be reused for future experiments.
- An interface for users to query the extracted data. We plan to reuse the existing web client tool by adding an ‘NLP’ ontology which contains all of the concepts that could be used to filter and joined with other ontologies such as demographics or codified data.
2.1 cTAKES GUI
2.1.1 Input
Users will be able to specify the source of the notes and flexible enough to also enter their custom own SQL.
- The DataSource of the notes should be a relational database such as MSSQL, Oracle, etc. In order for it to be formatted into the i2b2 observation_fact format, there are several main required fields: encounter_num, patient_num, start_date,provider_id, modifier_cd, observation_blob (These document properties be preserved and re-inserted into the observation_fact table.)
Example SQL: select o.[Sequence Number] as encounter_num, patient_num, observation_blob, start_date, provider_id, '@' as modifier_cd from observation_fact o
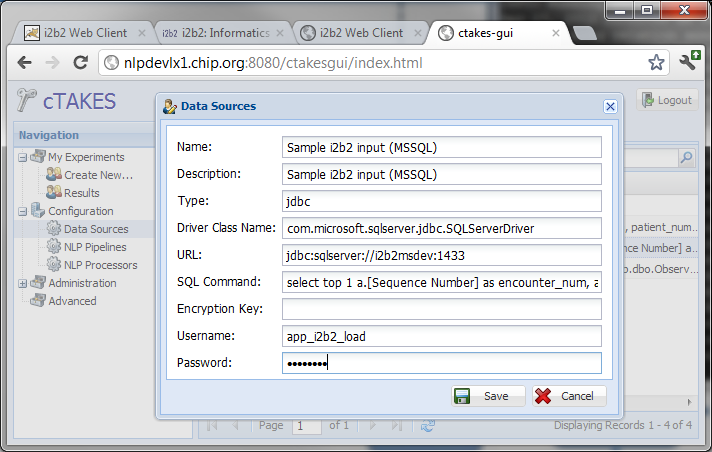
2.1.2
Output
- The DataSouce for the output should also be a relational database (specially designed to be the i2b2 observation_fact table itself.) However, the UI will allow users to specify exactly which DB/table they would like populated.
Example SQL template: insert into i2b2_stg_db.dbo.Observation_Fact_NLP (encounter_num,patient_num,concept_cd,provider_id,start_date,modifier_cd,valtype_cd,tval_char,nval_num,observation_blob) values (?,?,?,?,?,?,?,?,?,?) [Note: All of these fields are REQUIRED in order to populate the i2b2 output format correctly.]
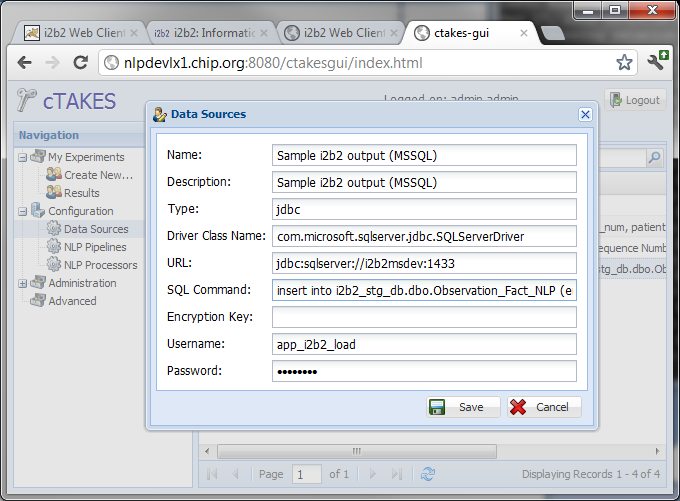
Example of formatted output:
Sample Narrative: “The patient did not have reflux.”
|
encounter_num |
patient_num |
concept_cd |
provider_id |
start_date |
modifier_cd |
valtype_cd |
tval_char |
nval_num |
observation_blob |
|
13486 |
1189799 |
SNO:155673008 |
2030 |
00:00.0 |
@ |
T |
-1 |
NULL |
reflux |
Note: Currently we using the tval_char value for polarity (negation) indicator. In the future, attributes of identified annotations may be stored as modifiers in separate rows.
2.1.3
The NLP processing pipeline
There will be a ‘Default NLP pipeline’ provided with the GUI. This NLP pipeline is specially designed only to include NLP code that is required for extracted identified concepts. This default plaintext clinical pipeline consists of:
SimpleSegmentAnnatator
SentenceDetectorAnnotator
TokenizerAnnotator
LVG Annotator
ContextDpendentTokenizerAnnotator
POSTagger
Chunker
LookupWindowAnnotator
UMLSDictionaryLookupAnnotator
StatusAnnotator
NegationAnnotator
ExtractionPrepAnnotator
Details regarding cTAKES pipelines and their individual Annotators could be found on the cTAKES documentation website: https://wiki.nci.nih.gov/display/VKC/cTAKES+%28Clinical+Text+Analysis+and+Knowledge+Extraction+System%29
Once the concepts has been extracted and stored into i2b2’s observation_fact table format, there are many ways it can be queried/exported. The example we will provide is adding additional NLP ontology for the i2b2 web client. This will allow users to query the presence of a specific concept and join it with existing ontologies such as Demographics/Age.
The user metadata (data describe the user configuration data) will be stored in a self-contained relational database (Hypersonic) embedded within the GUI.
3.1 Table
We are using the liquibase tool to manage the DDL’s of the cTAKES GUI configuration/metadata tables. The latest version could be found with the source code under: src/main/resources/db/1.xml.
Note: The target i2b2 observation_fact table is not included here, but could be found in i2b2’s core documentation.
< databaseChangeLog xmlns = "http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" xmlns:ext = "http://www.liquibase.org/xml/ns/dbchangelog-ext"
xsi:schemaLocation = "http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd
http://www.liquibase.org/xml/ns/dbchangelog-ext http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-ext.xsd" >
< changeSet author = "dev" id = "1" >
< createTable tableName = "CTAKES_USER" >
< column autoIncrement = "true" name = "id" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_User" />
</ column >
< column name = "userName" type = "varchar(100)" >
< constraints nullable = "false" unique = "true" />
</ column >
< column name = "name" type = "varchar(254)" />
< column name = "firstName" type = "varchar(254)" />
< column name = "email" type = "varchar(254)" >
< constraints nullable = "false" />
</ column >
< column name = "passwordHash" type = "varchar(80)" />
< column name = "locale" type = "varchar(8)" />
< column name = "enabled" type = "BOOLEAN" />
< column name = "createDate" type = "DATETIME" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "2" >
< createTable tableName = "CTAKES_ROLE" >
< column autoIncrement = "true" name = "id" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_Role" />
</ column >
< column name = "name" type = "varchar(50)" >
< constraints nullable = "false" />
</ column >
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "3" >
< createTable tableName = "CTAKES_USERROLES" >
< column name = "userId" type = "BIGINT" >
< constraints nullable = "false" />
</ column >
< column name = "roleId" type = "BIGINT" >
< constraints nullable = "false" />
</ column >
</ createTable >
< addPrimaryKey columnNames = "userId,roleId"
constraintName = "PK_UserRoles" tableName = "CTAKES_USERROLES" />
< addForeignKeyConstraint baseColumnNames = "userId"
baseTableName = "CTAKES_USERROLES" constraintName = "FK_UserRoles_User"
referencedColumnNames = "id" referencedTableName = "CTAKES_USER" />
< addForeignKeyConstraint baseColumnNames = "roleId"
baseTableName = "CTAKES_USERROLES" constraintName = "FK_UserRoles_Role"
referencedColumnNames = "id" referencedTableName = "CTAKES_ROLE" />
</ changeSet >
< changeSet author = "dev" id = "4" >
< insert tableName = "CTAKES_ROLE" >
< column name = "name" value = "ROLE_ADMIN" />
</ insert >
< insert tableName = "CTAKES_ROLE" >
< column name = "name" value = "ROLE_USER" />
</ insert >
</ changeSet >
< changeSet author = "dev" id = "5" >
< createTable tableName = "CTAKES_CONFIG_PARAM" >
< column name = "param_name" type = "varchar(254)" >
< constraints nullable = "false" unique = "true" />
</ column >
< column name = "param_value" type = "varchar(254)" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "6" >
< createTable tableName = "CTAKES_CONFIG_DATASOURCE" >
< column autoIncrement = "true" name = "id" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_datasource_id" />
</ column >
< column name = "name" type = "varchar(254)" />
< column name = "description" type = "varchar(254)" />
< column name = "ds_type" type = "varchar(254)" />
< column name = "ds_driverclass" type = "varchar(254)" />
< column name = "ds_url" type = "varchar(254)" />
< column name = "ds_col_name" type = "varchar(254)" />
< column name = "ds_table_name" type = "varchar(254)" />
< column name = "ds_sql" type = "varchar(5000)" />
< column name = "ds_encryption_key" type = "varchar(254)" />
< column name = "ds_username" type = "varchar(254)" />
< column name = "ds_password" type = "varchar(254)" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "7" >
< createTable tableName = "CTAKES_CONFIG_NLP_PROCESSOR" >
< column autoIncrement = "true" name = "id" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_processor_id" />
</ column >
< column name = "name" type = "varchar(254)" />
< column name = "description" type = "varchar(254)" />
< column name = "classname" type = "varchar(254)" />
< column name = "desc_config_path" type = "varchar(254)" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "8" >
< createTable tableName = "CTAKES_CONFIG_NLP_PROCESSOR_FLOW" >
< column autoIncrement = "true" name = "id" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_processor_flow_id" />
</ column >
< column name = "name" type = "varchar(254)" />
< column name = "description" type = "varchar(254)" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "9" >
< createTable tableName = "CTAKES_CONFIG_NLP_PROCESSOR_MAPPING" >
< column autoIncrement = "true" name = "id" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_processor_mapping_id" />
</ column >
< column name = "flow_id" type = "BIGINT" />
< column name = "processor_id" type = "BIGINT" />
< column name = "processor_order" type = "INT" />
< column name = "name" type = "varchar(254)" />
< column name = "description" type = "varchar(254)" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "10" >
< createTable tableName = "CTAKES_CONFIG_DICTIONARY" >
< column autoIncrement = "true" name = "id" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_dictionary_id" />
</ column >
< column name = "name" type = "varchar(254)" />
< column name = "description" type = "varchar(254)" />
< column name = "lastmodifiedby" type = "varchar(254)" />
< column name = "lastmodified" type = "datetime" />
< column name = "created" type = "varchar(254)" />
< column name = "createdby" type = "varchar(254)" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "11" >
< createTable tableName = "CTAKES_CONFIG_DICTIONARY_ENTRY" >
< column name = "id" autoIncrement = "true" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_dictionary_entry_id" />
</ column >
< column name = "dictionary_id" type = "BIGINT" />
< column name = "fword" type = "varchar(254)" />
< column name = "text" type = "varchar(1024)" />
< column name = "code" type = "varchar(254)" />
< column name = "cui" type = "varchar(254)" />
< column name = "tui" type = "varchar(254)" />
< column name = "source" type = "varchar(254)" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "12" >
< createTable tableName = "CTAKES_CONFIG_DICTIONARY_MAPPING" >
< column name = "entry_code" type = "varchar(254)" />
< column name = "entry_cui" type = "varchar(254)" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "13" >
< createTable tableName = "CTAKES_EXPERIMENT" >
< column autoIncrement = "true" name = "id" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_experiment_id" />
</ column >
< column name = "name" type = "varchar(254)" />
< column name = "description" type = "varchar(254)" />
< column name = "datasource_id" type = "BIGINT" />
< column name = "output_format" type = "varchar(50)" />
< column name = "destination_ds_id" type = "BIGINT" />
< column name = "processor_flow_id" type = "BIGINT" />
< column name = "dictionary_id" type = "BIGINT" />
< column name = "lastmodifiedby" type = "varchar(254)" />
< column name = "lastmodified" type = "datetime" />
< column name = "created" type = "varchar(254)" />
< column name = "createdby" type = "varchar(254)" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "14" >
< createTable tableName = "CTAKES_EXPERIMENT_RESULT" >
< column autoIncrement = "true" name = "id" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_result_id" />
</ column >
< column name = "experiment_id" type = "BIGINT" />
< column name = "doc_id" type = "varchar(254)" />
< column name = "concept_type" type = "varchar(254)" />
< column name = "concept_name" type = "varchar(1024)" />
< column name = "concept_value" type = "varchar(5120)" />
< column name = "concept_start" type = "BIGINT" />
< column name = "concept_end" type = "BIGINT" />
< column name = "lastmodifiedby" type = "varchar(254)" />
< column name = "lastmodified" type = "datetime" />
</ createTable >
</ changeSet >
< changeSet author = "dev" id = "15" >
< createTable tableName = "CTAKES_EXPERIMENT_RESULT_ATTRS" >
< column autoIncrement = "true" name = "id" type = "BIGINT" >
< constraints nullable = "false" primaryKey = "true"
primaryKeyName = "PK_result_attr_id" />
</ column >
< column name = "result_id" type = "BIGINT" />
< column name = "attr_name" type = "varchar(254)" />
< column name = "attr_value" type = "varchar(254)" />
< column name = "attr_type" type = "varchar(254)" />
< column name = "lastmodifiedby" type = "varchar(254)" />
< column name = "lastmodified" type = "datetime" />
</ createTable >
</ changeSet >
</ databaseChangeLog >
Data Objects in the cTAKES GUI are represented as Java DAO’s Hibernate and are injected by the Spring Framework. These entities and repository could be found in the org.chboston.cnlp.ctakes.gui.entity and repository packages.
The web interface is build on top of an existing javascript framework (ExtJS). These objects are also represented in the MVC pattern in javascript. These objects are exposed via ExtDirect services library which maps javascript calls directly to the Java backed code/methods.
The full original note should not be persisted locally by the GUI. Rather, it should read through the note, extract the identified annotations, and only store the identified annotations (either embedded or back to i2b2’s DB).
The cTAKES GUI is designed to be an administrative tool. The user should be an Admin have read/write rights to the input and target DataSources.
There is built in encryption support by the cTAKES GUI. i.e. If the original note stored in the i2b2 observation_blob was encrypted, there will be a configurable input field in the GUI for the users to specify the required key for decryption (The existing i2b2’s Encryption Java API’s are reused).
Processing:
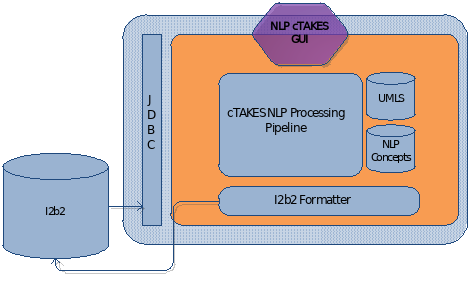
Web Client:

- Technologies used
- Java 6
- cTAKES
- UIMA
- ExtJS (Javascript UI framework)
- ExtDirect
- Spring
- Jetty/Servlet Container
- Liquibase
- Hypersonic Embedded Database
- Limitations
- Currently, the GUI and the NLP processing are bundled and process together, therefore limited to only 1 thread/1 instance of the pipeline per container. In the future, these 2 components will be decoupled where the GUI only saves the jobs, and off loads the NLP pipeline processing in a separate process.
- Currently, we are populating the polarity (negation) attribute in the tval_char field. In the future, these attributes may be stored as modifiers.
- Currently, we support the extract the concepts defined in the full 2011AB UMLS SNOMED-CT and RxNorm (w/Thesauruses from SNOMED CT® , NCI Thesaurus , Medical Subject Headings (Mesh), RxNorm ). There is a placeholder to allow users to enter in their own dictionaries but has not been implemented yet.
- Note: The cTAKES GUI was designed to output the data in the i2b2 format. However, it can also be run as a stand-alone UI where the data could be outputted to other RDMS or its embedded DB where it could be queried via standard SQL.
{kind=link}