Page History
About the "CARE - Concept Demographics Histograms" Web Client Plugin
Introduction
This plugin is part of the CARE (Cohort Analysis & Refinement Expeditors) Tool Set developed as a result of feedback and suggestions from the i2b2 users community in the University of Massachusetts Medical School. As its name implies, the purpose of this tool set is to facilitate and expedite the analysis of the cohorts (i.e. a subset of a patient set) and therefore hopefully the refined usage of those particular cohorts in a study.
...
- Navigate to the "Specify Data" tab. Drag and drop a Patient Set and one or more concepts (ontology terms) onto the appropriate input boxes:## Enter appropriate values in the 'Starting Patient' and 'Number of Patients' fields that are then presented, to specify the subset of the patient set to use. Also specify at the 'Query Subgroup Size' field the size of smaller queries of subgroups of patients to be used iteratively, to facilitate reducing the risks of overwhelming the server (i2b2 hive).## Click on the corresponding 'HELP' hotlinks next to the 'Starting Patient' and 'Number of Patients' fields, and the'HELP' hotlink next to the 'Query Subgroup Size' field, for detailed information; and enter corresponding appropriate values.## Click on the corresponding 'HINT' hotlink below the 'Concepts' field for hint or suggestion for selecting concepts.
- Then, select the "View Results" tab to wait for and view the generated demographic histograms.
- Finally, select the "Export Data" tab to click the appropriate button to download the histogram data, in the desired form, to the local computer.

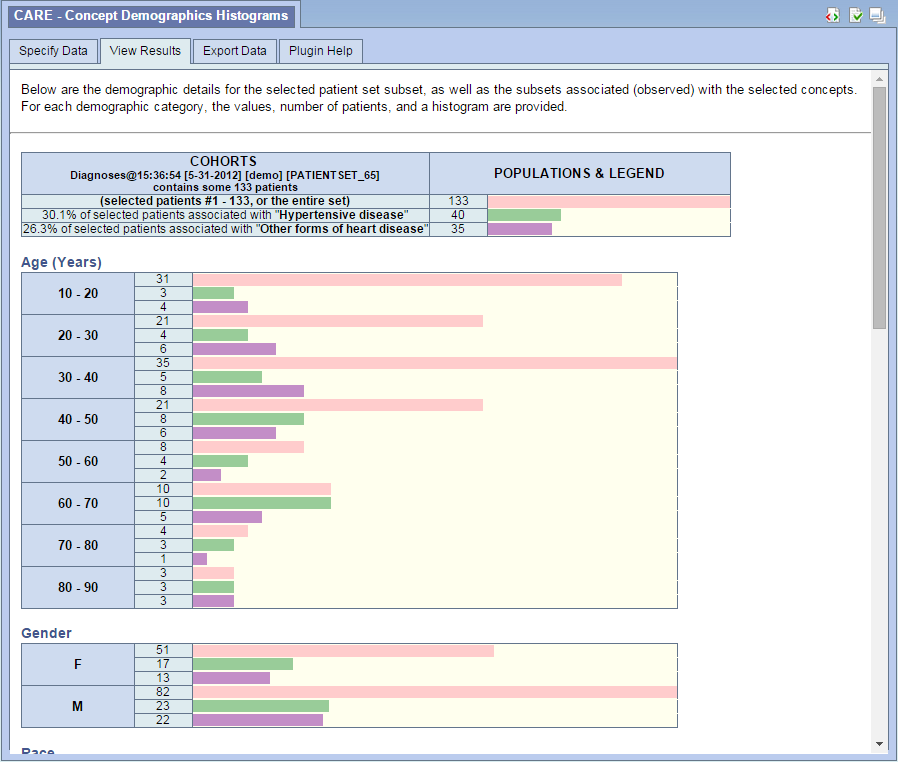
Result Example
Caveats
- Since it is possible for the server (i2b2 hive) to take a long time to provide all the data requested, this plugin provides occasional updates of 'Elapsed time' and 'estimated remaining run time', etc. displays while the data are being fetched. These displayed values are at best rough estimates based on occasional data coming back from the server. In the case of zero 'Query Subgroup Size' selected (i.e. no query-subgrouping), then there would be no data coming back from the server until either of the following situations:
- The whole, single, query is done.
- The server itself started paging (i.e. query-subgrouping), and the result of the 1st of such paged subqueries just arrived.
- The server got overwhelmed by all the excessive data and failed, returning an 'error'.
- In any of these cases above, the updates of 'Elapsed time' and 'estimated remaining run time' will be quite infrequent, as updates from the server (i2b2 hive) will most likely take a long time, and far and few in-between, if any.
- This plugin also tries to provide updates on the current subgroup the server (i2b2 hive) is fetching. However, in the cases when the server (i2b2 hive) itself started paging (i.e. query-subgrouping), then the current subgroup # being fetched may exceed the original stated total number of subgroups.
- The exact behaviors of exporting data in the desired files will be different among the various browsers (Firefox, Chrome, Internet Explorer, Safari, and Opera). Most of these browsers will present options between saving and just opening the exported file; while certain browsers, like Internet Explorer, may also open up a new blank tab page along with the export action.
...
1.0 | Initial release, with options of using a subset of a large patient set; user-friendly feedback (estimated run-time, etc.), helps & hints. | 2015 Q1 |
1.0.1 | Improved displays of the "COHORTS vs. POP. & LEGEND" table in the "View Results" tab on Internet Explorer 32/64. | 2015 Q2 |
1.1 | Added "Export Data" options & other minor refinements. | 2015 Q2 |
...
Terms of Use
This plugin is published under the GNU GPL v3 license.
...
{kind=link}